DeAltHDR: Learning HDR Video Reconstruction from Degraded Alternating Exposure Sequences
ICLR 2026¹Harbin Institute of Technology, Harbin, China
²City University of Hong Kong, Hong Kong
Abstract
High dynamic range (HDR) video can be reconstructed from low dynamic range (LDR) sequences with alternating exposures. However, most existing methods overlook the degradations (e.g., noise and blur) in LDR frames, focusing only on the brightness and position differences between them. To address this gap, we propose DeAltHDR, a novel framework for high-quality HDR video reconstruction from degraded sequences.
Our framework addresses two key challenges. First, noisy and blurry contents complicate inter-frame alignment. To tackle this, we propose a flow-guided masked attention mechanism that leverages optical flow for a dynamic sparse cross-attention computation, achieving superior performance while maintaining efficiency. Notably, its controllable attention ratio allows for adaptive inference costs. Second, the lack of real-world paired data hinders practical deployment. We overcome this with a two-stage training paradigm: the model is first pre-trained on our newly introduced synthetic paired dataset and subsequently fine-tuned on unlabeled real-world videos via a proposed self-supervised method.
Experiments show our method outperforms state-of-the-art ones. Code and data will be available at https://zhang-shuohao.github.io/DeAltHDR/.
DeAltHDR Overview
Comparison with HDRFlow, which is a representative state-of-the-art method that balances performance and efficiency. Our DeAltHDR outperforms it while the inference cost can be adjusted.
Method Overview

Overview of our framework. Figure (a) illustrates the processing of the t-th frame in our DeAltHDR, where DeAltHDR uses the other 2 neighboring frames for assistance. Taking the alignment from (t-1)-th frame to t-th frame as an example, figure (b) shows how Flow-Guided Mask Attention Alignment (FGMA) works.
Quantitative Comparisons
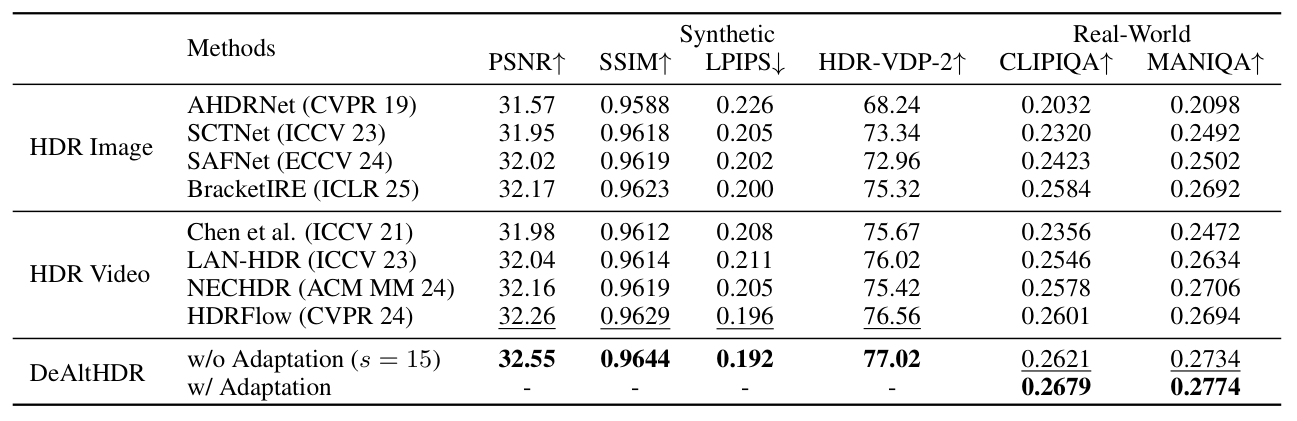
Quantitative comparison with state-of-the-art HDR restoration methods on both synthetic and real-world datasets. The best results are bolded, and the second-best results are underlined.
Visual Comparisons

Visual comparison on DeepHDRVideo dataset.

Visual comparison on Real-HDRV dataset.
Representative Results and Inputs
Each row shows a short-exposure/long-exposure input pair and the reconstructed HDR result from DeAltHDR.